吴恩达 Claude Code 教程 03:深入代码库与 AI 记忆的构建
- 作者:手工川(南川同学)
- 创建于 2025年8月16日,最后更新于 2025年8月16日
- 分类:AI 工具
- 标签:Claude Code转载AI
- 所属系列:吴恩达 Claude Code 笔记
- 转载自微信公众号「手工川」· 第 3 期
转载声明:本文系转载自微信公众号「手工川」的《吴恩达 Claude Code 笔记》第 3 期。原文版权归作者与公众号所有;正文整理自 DeepLearning.AI 与 Anthropic 官方课程材料。若需商业使用请联络原作者。 原文链接:在微信中打开 · 专辑目录
欢迎来到吴恩达与 Anthropic 官方合作课程的第三期。在 上一期 中,我们体验了 Claude Code 从零到一的创造力,并完成了环境配置。
今天,我们将进入一个更真实的开发场景:接手一个已有的、功能复杂的 RAG (检索增强生成) 聊天机器人项目。我们将学习如何利用 Claude Code 快速理解代码库、梳理复杂逻辑,并为其构建一套持久化的“记忆”——CLAUDE.md 文件系统。
手工川注:
- 本文我们基于官方文档对视频内容中的 CLAUDE.md 做了更加全面的讲解
- 个人也推荐大家可以使用 ascii 去画原型,参考:和 Claude Code 讨论产品的界面和交互设计
- 上下文管理其实是个慢工细活,它核心的议题是“”
项目实战:与 RAG 聊天机器人代码库的初次对话
我们面临的项目是一个能与 DeepLearning.AI 课程资料对话的 RAG 聊天机器人。在不了解任何代码细节的情况下,我们的首要任务是快速建立对项目整体的认知。
从高层问题入手
我们无需逐个文件阅读,而是直接向 Claude Code 提出一个高层次的问题,例如:
“Give me an overview of the codebase.” (给我一份代码库的概述。)
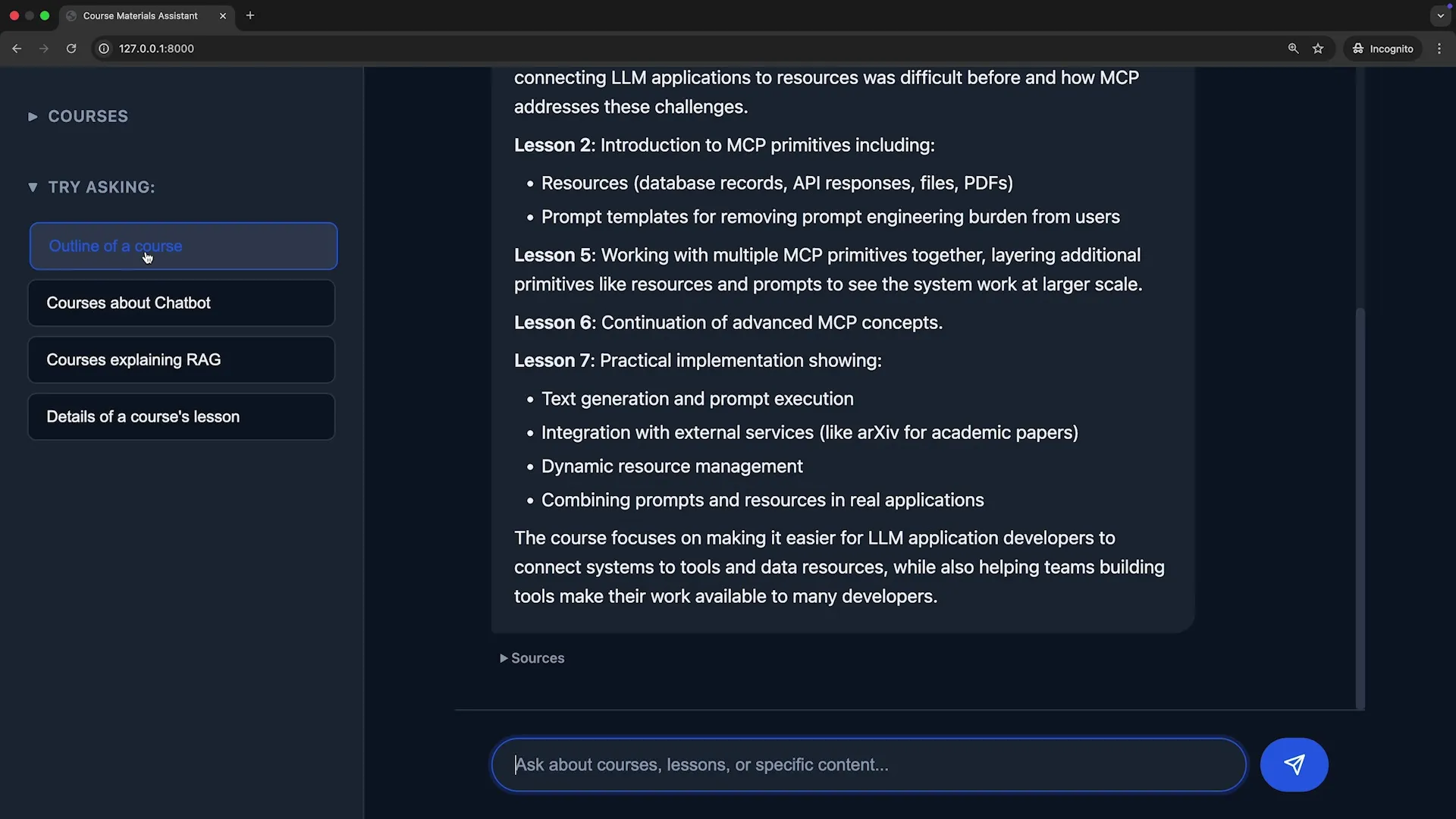
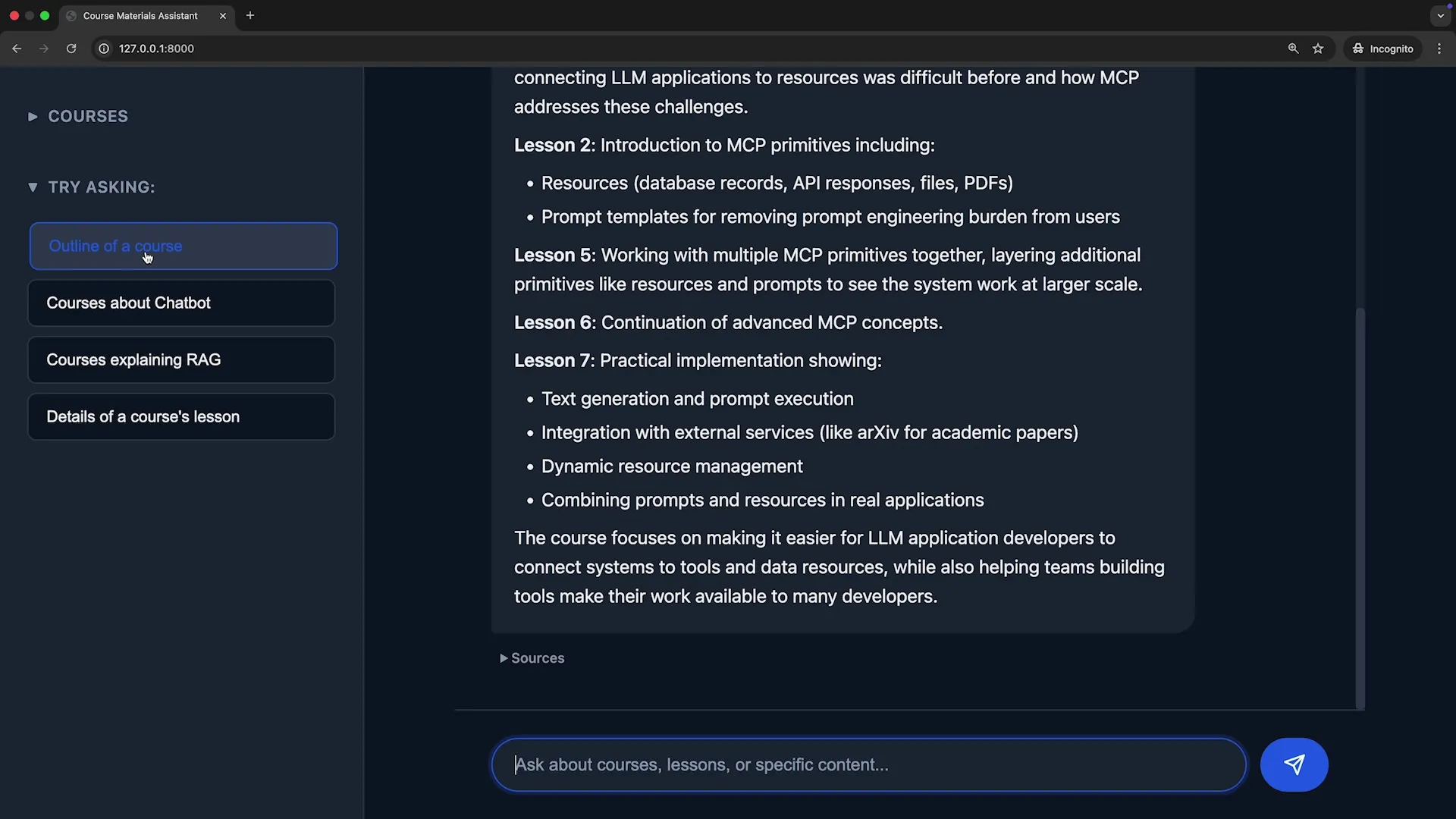
Claude Code 会立即启动它的 “智能体搜索” (Agentic Search) 机制,智能地识别出项目中的关键文件,并为我们提炼出一份包含 项目架构、关键组件、主要功能 的摘要。
我们可以进一步追问,比如深入了解 RAG 的实现细节:
“How are these documents processed?” (这些文档是如何被处理的?)
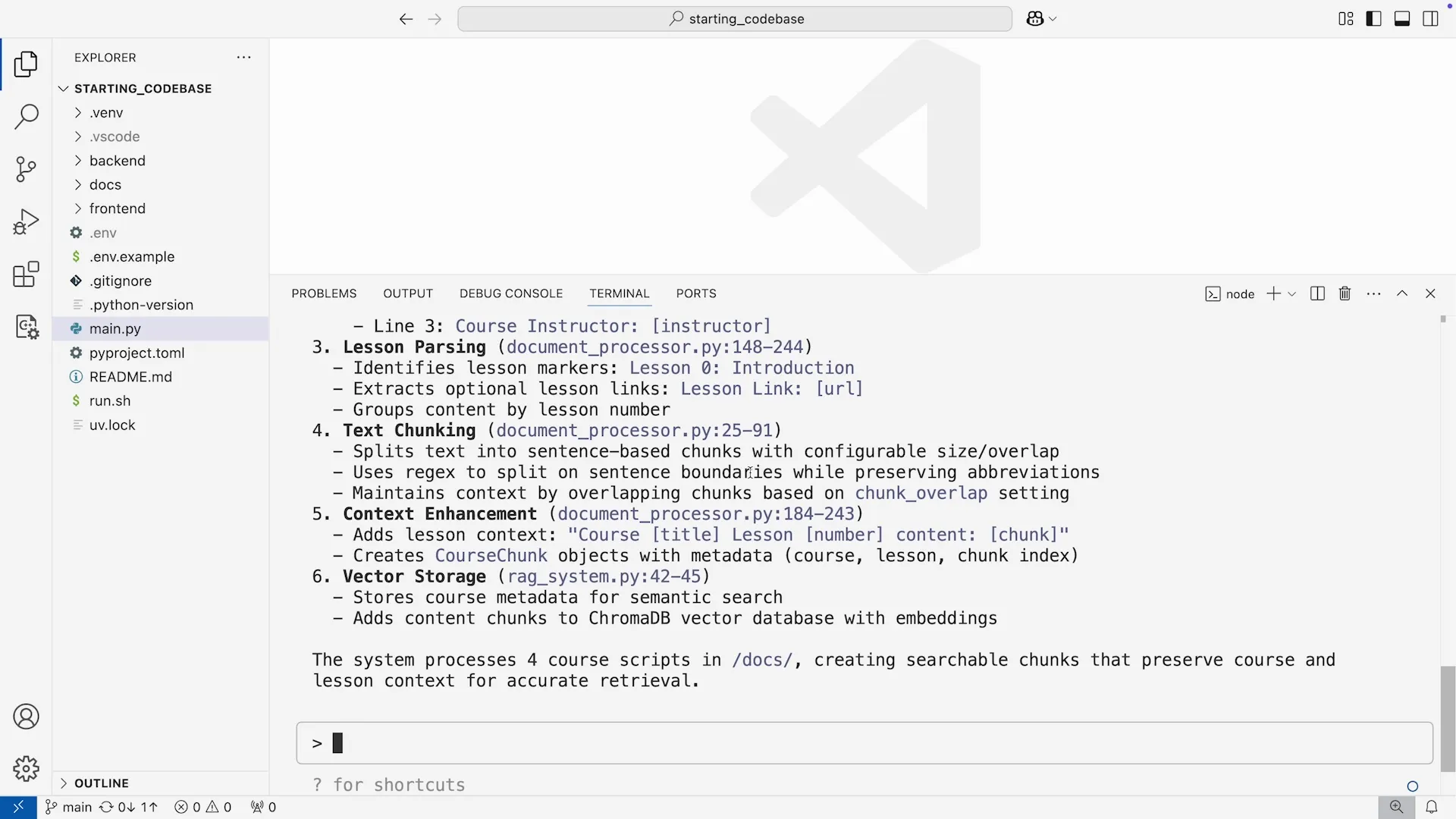
Claude Code 会精准定位到处理文本分块、添加上下文、存储元数据的相关代码,并清晰地解释整个流程。这个过程充分证明了:Claude Code 不仅是一个出色的工程师,更是一个卓越的解说员。
从文本到图表:让 AI 解释复杂流程
对于一个 Web 应用,理解用户请求从前端到后端的完整链路至关重要。我们可以让 Claude Code 为我们追踪这一流程:
“Trace the process of handling a user’s query from front end to back end.” (追踪处理用户查询从前端到后端的全过程。)
在执行过程中,Claude Code 会展示一个清晰的 “待办事项列表”,让我们了解它的思考路径。它会依次分析前端代码、API 接口、RAG 系统,最终生成一份详尽的步骤分解。
然而,纯文本有时不够直观。我们可以提出一个更有趣的要求:
“Draw a diagram that illustrates this flow.” (画一张图表来阐释这个流程。)
Claude Code 会在终端中为我们生成一幅 ASCII 艺术图表。这是一种非常实用的方式,无需离开命令行环境,就能对复杂系统流程一目了然。
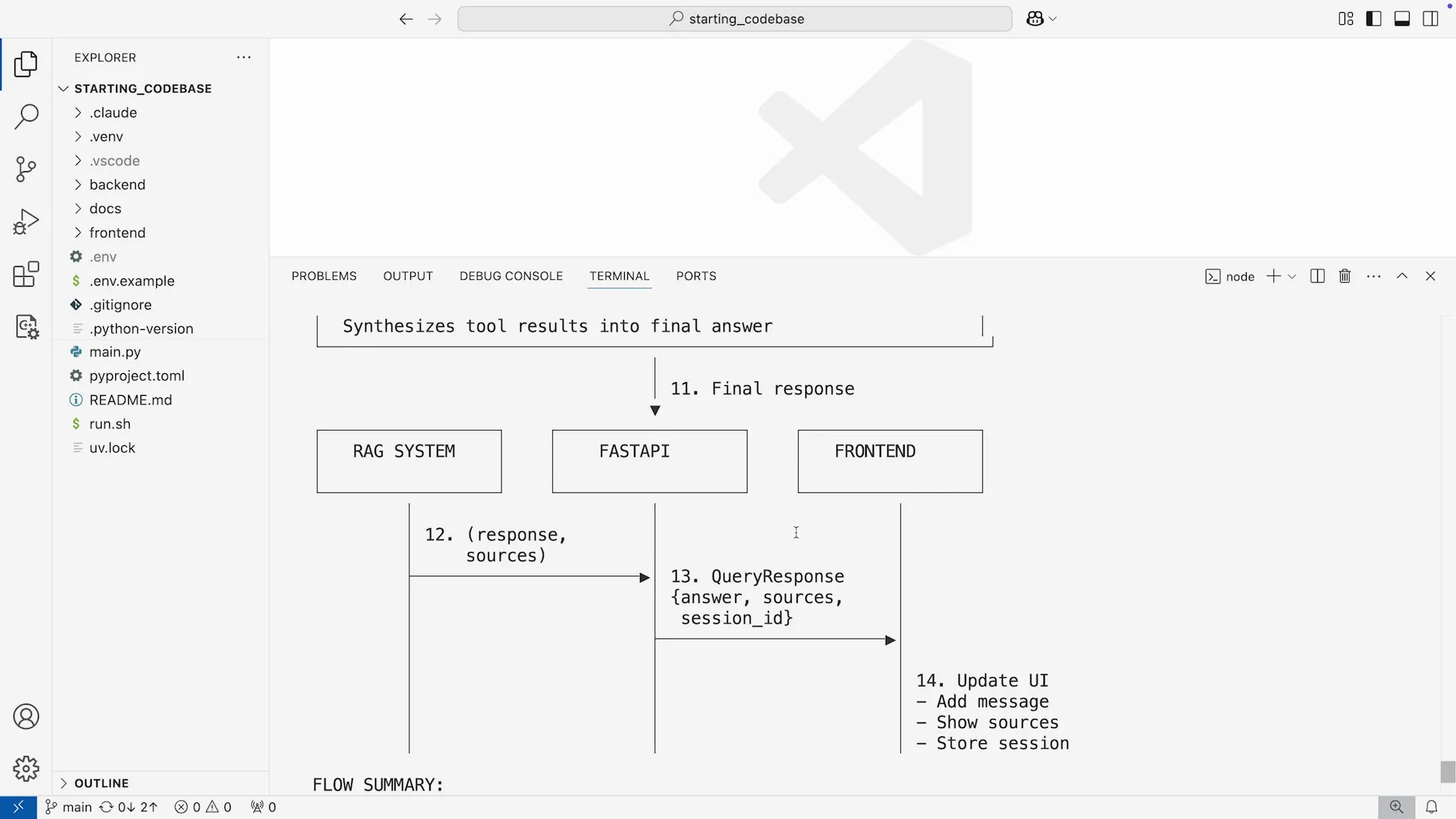
这幅图清晰地展示了从前端请求、后端处理、向量数据库 (Chroma DB) 检索,到最终由大模型生成响应的全过程。尽管只是字符画,但信息量十足。当然,如果我们有需要,也可以要求它生成用于 Web 的 D3.js 或 Recharts 代码,来创建更丰富的可视化图表。
核心机制:构建 Claude 的长期记忆 (CLAUDE.md)
到目前为止,我们与 Claude Code 的所有交互都是基于当前会话的。为了让 AI 能够“记住”项目的关键信息和我们的特定偏好,我们需要引入其核心的记忆机制——CLAUDE.md 文件系统。
初始化项目记忆
我们推荐在接手任何新项目时,首先运行 /init 命令。
> /init这个命令会自动分析整个代码库,并生成一个初始的 CLAUDE.md 文件。这个文件是 至关重要的,它承载了 Claude Code 在本项目中的长期记忆。
记忆的层级与加载机制
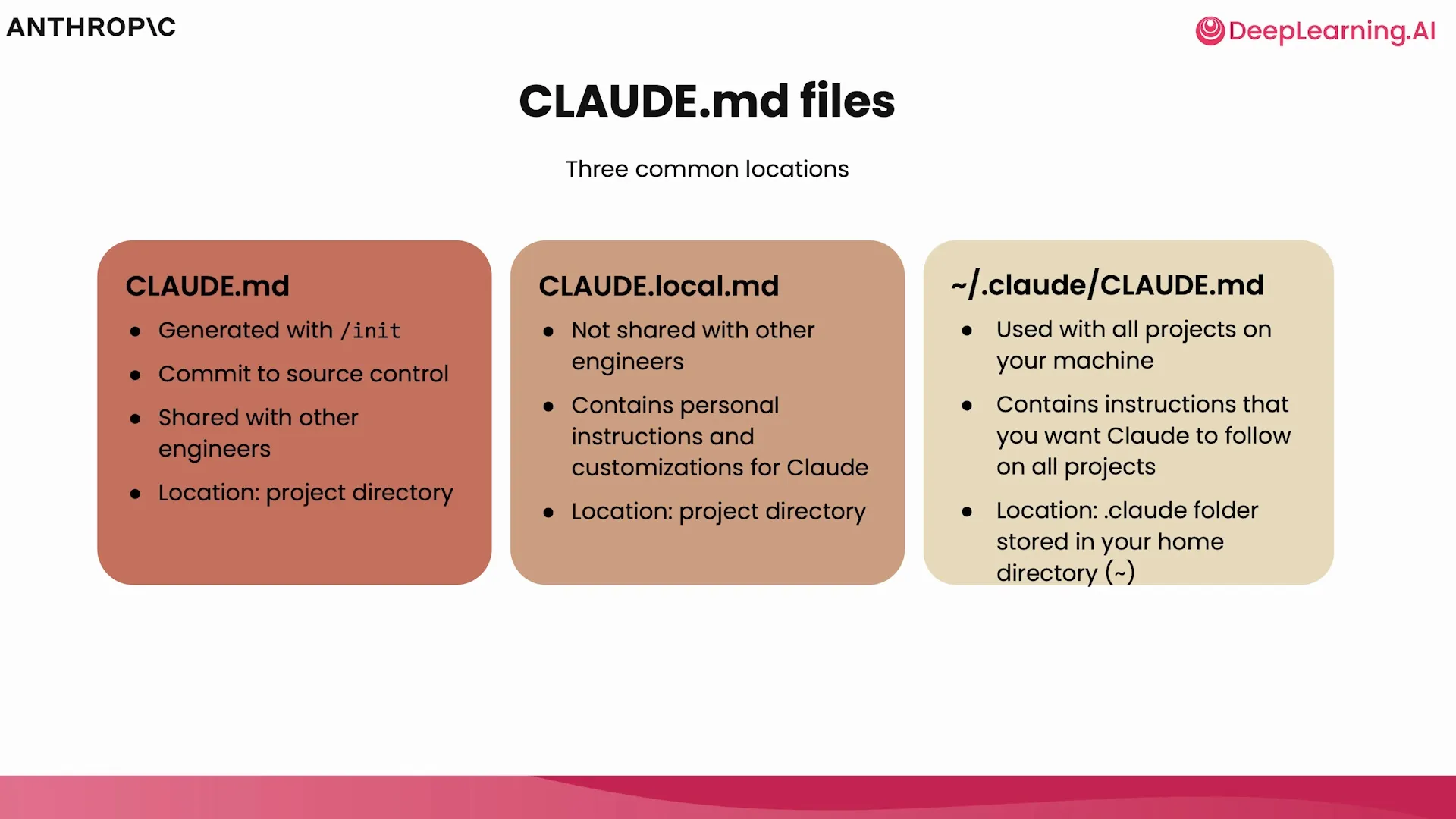
CLAUDE.md 文件系统并非单一文件,而是一个分层的体系,以满足不同范围的需求。理解这个体系对于高效使用 Claude Code 至关重要。
| 记忆类型 | 文件位置 | 目的与用途 | 共享范围 |
|---|---|---|---|
| 企业策略 | 系统级目录 (如 /etc/claude-code/) | 由 IT/DevOps 管理的全公司范围的指令 | 组织内所有用户 |
| 项目记忆 | ./CLAUDE.md | 团队共享的项目特定指令,应提交到版本控制 | 所有项目成员 |
| 用户记忆 | ~/.claude/CLAUDE.md | 适用于你所有项目的个人偏好 | 仅自己 (所有项目) |
| 本地项目记忆 | ./CLAUDE.local.md | 个人在当前项目中的特定偏好 (已被废弃) | 仅自己 (当前项目) |
加载机制:Claude Code 会从当前工作目录开始,向上递归查找 CLAUDE.md 文件,直到根目录。同时,它也会加载全局的用户记忆和企业策略。高层级的记忆会先被加载,形成基础上下文,然后被更具体的低层级记忆覆盖或补充。
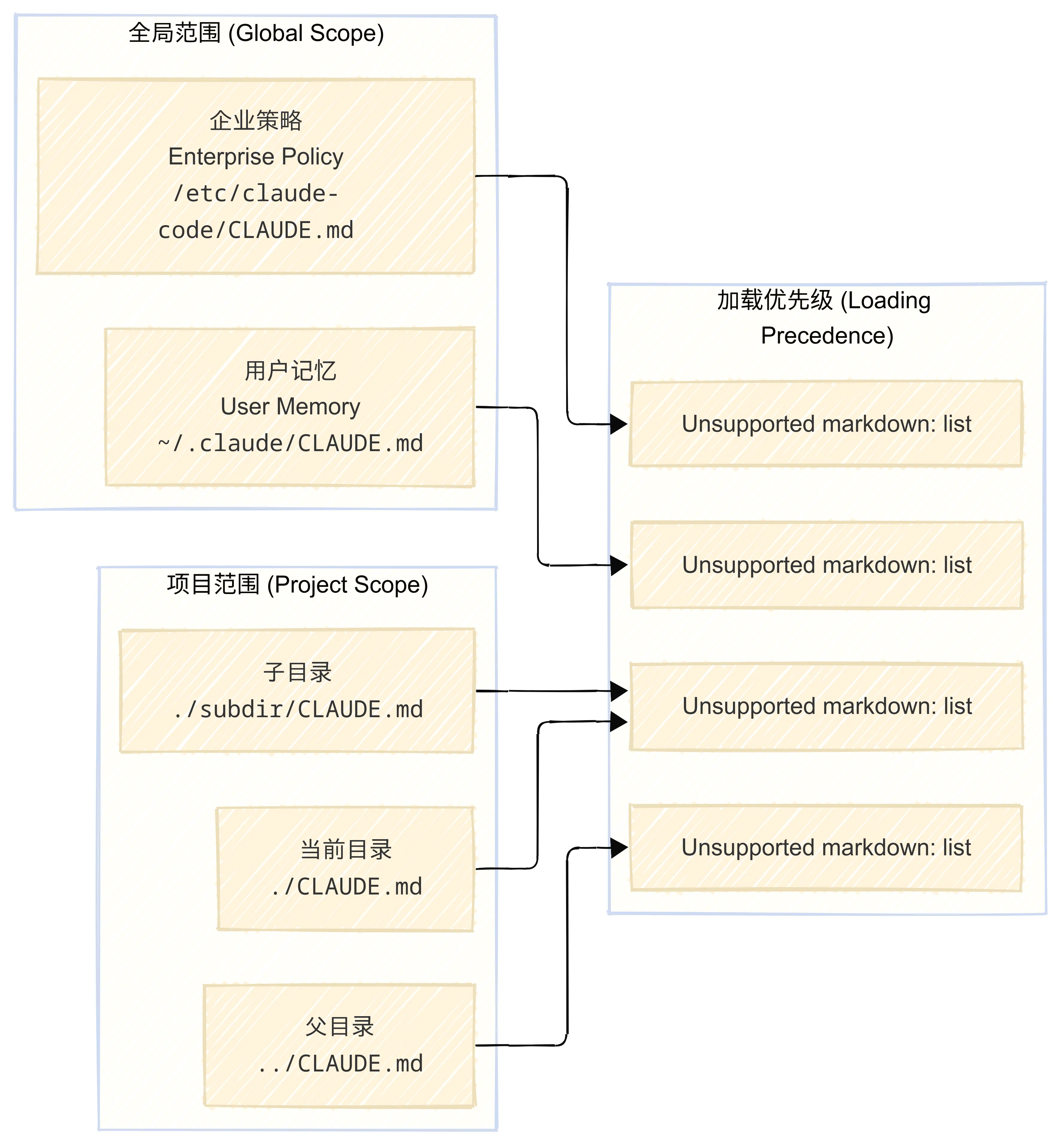
重要更新:根据最新文档,原有的 CLAUDE.local.md 文件已被废弃。现在推荐使用 import 语法 在主 CLAUDE.md 文件中引入个人配置文件,例如 @~/.claude/my-project-instructions.md。这种方式对 Git worktrees 的支持更好。
动态更新记忆
除了编辑文件,我们还可以使用 # 快捷指令在对话中快速添加记忆。例如,我们的项目推荐使用 uv 作为包管理器,为了防止 Claude 使用 pip,我们可以这样指示:
# Always use UV to run the server, do not use pip directly.手工川注:我们今年的 python 项目也在迁移到 uv 管理。
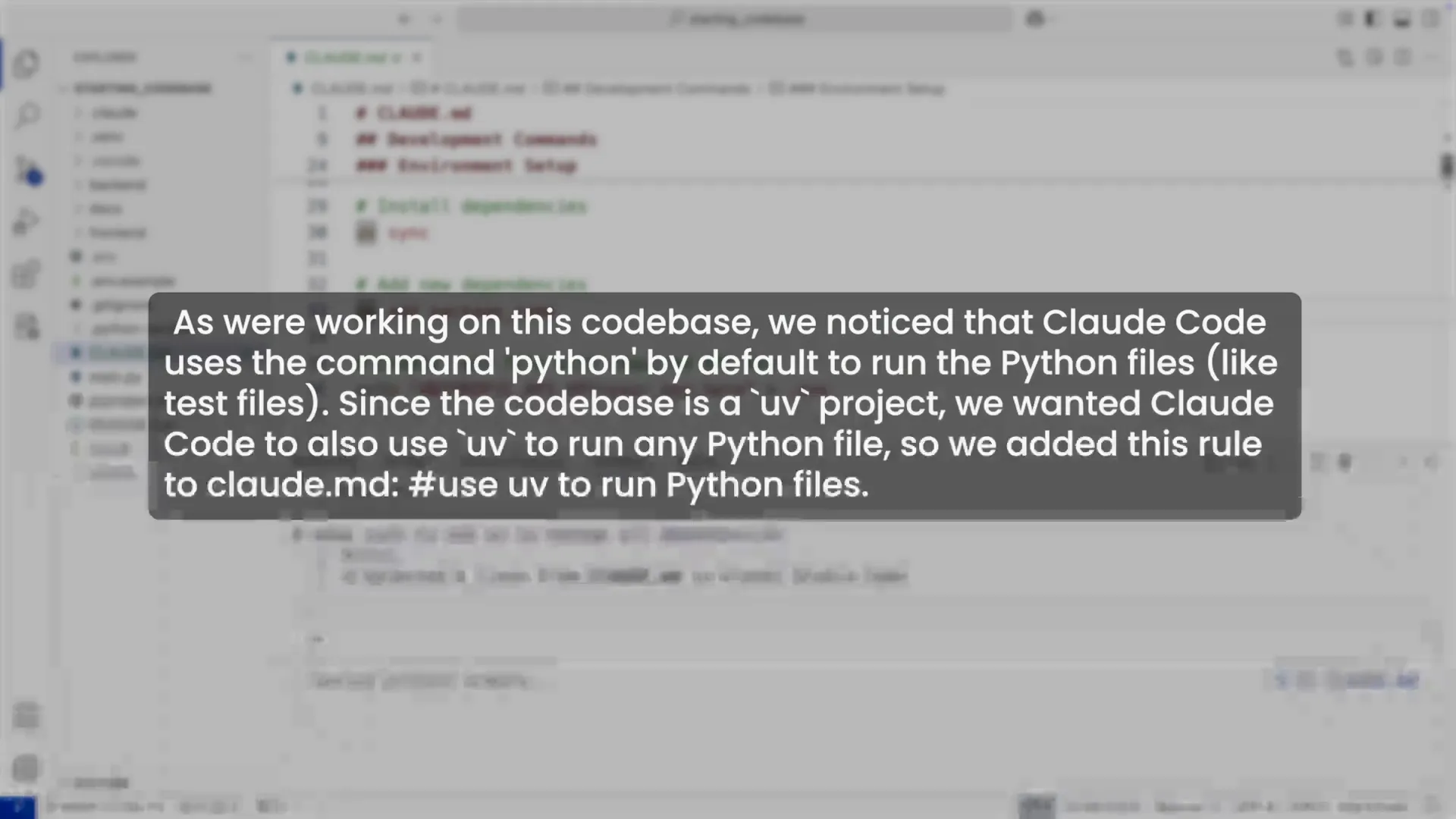
Claude Code 会询问你希望将这条记忆保存在哪个文件中(项目、本地或用户),选择后,CLAUDE.md 文件就会被自动更新。
高效交互:常用命令与 Git 集成
Claude Code 还提供了一系列内置命令来提升交互效率。
/help: 显示所有可用命令的帮助信息。/clear: 完全清空当前对话历史,开始一个全新的上下文。/compact: 清空历史,但保留一份摘要,以便在新的对话中延续之前的背景。/ide: 连接到你的 IDE (如 VS Code),让 Claude 知道你当前正在查看或编辑哪个文件。Esc键: 随时中断 Claude 正在执行的任何任务。
与 Git 的无缝集成
一个非常实用的功能是 Claude Code 与 Git 的深度集成。当你完成了一些修改后,不必再手动编写 git add 和 git commit 命令。
你可以直接让 Claude Code 帮你提交更改。它不仅会执行 Git 命令,还会根据本次修改的内容,自动生成一段 高质量、描述性强的 commit message。这对于维护清晰的版本历史和团队协作非常有价值。
手工川结语
本期课程我们完成了从理论到实践的跨越。我们学会了如何利用 Claude Code 探索一个真实、复杂的代码库,通过提问和图表生成快速掌握其核心逻辑。更重要的是,我们深入了解了 CLAUDE.md 这一核心记忆系统,学会了如何通过分层配置和动态更新,将 AI 助理调教成最懂你项目的专家。
掌握了这些基础,我们已经准备好让 Claude Code 真正为我们“动手”了。下一期,我们将开始为这个 RAG 聊天机器人添加全新的功能。敬请期待!